Best paper award for Inês Xavier (Economics ’15, UPF PhD ’21)
Congratulations to @Ines_MXavier for winning the @ITAXjournal Best PhD student paper award for her paper "Wealth Inequality in the US: The Role of Heterogenous Returns".
— International Tax and Public Finance (@ITAXjournal) August 26, 2021
Paper abstract
Why is wealth so concentrated in the United States? In this paper, I investigate the role of return heterogeneity as a source of wealth inequality. Using household-level data from the Survey of Consumer Finances (1989-2019), I provide new empirical evidence on returns to wealth in the United States, and find that wealthier households earn, on average, higher returns: moving from the 20th to the 99th percentile of the wealth distribution raises the average yearly return from 3.6% to 8.3%. To understand how these return differences shape the distribution of wealth, I introduce realistic return heterogeneity in a partial equilibrium model of household saving behavior. This exercise suggests that considering both earnings and return heterogeneity can fully account for the top 10% wealth share observed in the data (76%), which cannot be explained by earnings differences alone.
Gradual institutional change analyses have allowed drawing a more flexible line between stability and transformation when examining how institutions evolve over time, particularly in the absence of major critical junctures or exogenous shocks. Yet, the explanatory power of the theory has been undermined by a lack of attention to the overlapping boundaries of the modes of gradual institutional change, a relatively static model of agency, and conceptual confusion regarding what the modes of change exactly are.
In our recent article “Discursive Strategies and Sequenced Institutional Change: The Case of Marriage Equality in the United States” published in Political Studies, Tània Verge and I argue that addressing these shortcomings requires investigating the agent-based dynamics underpinning gradual institutional change and bringing to the fore the role of ideas. Indeed, ideas and discourses can have a constitutive impact in the creation, maintenance and reform of institutions, and actors strategically reframe problems and redirect solutions to influence both the process and the outcome of policy reforms.
Employing marriage equality in the United States as a case study, we show that the modes of gradual institutional change can be studied simultaneously as processes that unfold over time, often in a sequential fashion, as outcomes of these processes, and as strategies pursued by actors to steer, impede or undermine policy change.
Our results reveal that proponents and opponents of marriage equality have deployed discursive frames to legitimize institutional change to take off sequentially in a progressive direction — through the modes of “layering“ and “displacement“ — and in a regressive direction — through the mode of “conversion“.
Throughout this sequenced process, opposing actors have not only adjusted their discursive strategies to both their rivals and the targeted institutional venues, but have also shifted roles as change and status quo agents. Indeed, our study shows that the actors contesting the institutional status quo in one stage may become the actors defending it in a subsequent phase of the institutional change process, and vice versa. Thus, we argue that traditional, static conceptualizations of agency should be problematized and, rather than as resistance to gender-friendly reforms, opposition to marriage equality should be understood as a proactive mobilization to transform existing institutions.
The recent US Supreme Court decision in Fulton v. City of Philadelphia (2021) in favor of a Catholic foster care agency that refuses to work with same-sex couples, should then be understood as a victory of the years-long conservative strategy to undermine LGBT couples’ newly recognized right to marry.
Lastly, our study highlights the role of private actors as ideational entrepreneurs in the adoption and implementation of “morality policies,“ such as marriage equality. While morality policy scholars have so far predominantly examined how governmental actors shape policymaking, we show that the discursive strategies deployed by LGBT advocates, religious-conservative organizations and other private actors, such as foster care agencies, florists, and bakers, created new opportunities to influence policy debates and tip the scales to their preferred policy outcome.
Nils Handler ’18 presents the D\carb Future Economy Forum
I recently founded the D\carb Future Economy Forum with the goal of better informing the public debate on climate change on topics such as green growth, green macroeconomics and green innovation.
D\carb is strongly inspired by my Master’s studies at Barcelona GSE such as Antonio Ciccone’s class on Economic Growth and Albert Bravo-Biosca’s course on innovation policy.
Our speakers were Prof. Ottmar Edenhofer, Director and Chief Economist of the Potsdam Institute for Climate Impact Research, and Prof. Cameron Hepburn, Director of the Economics of Sustainability Programme and Professor of Environmental Economics at the University of Oxford. Johanna Schiele, McCloy-fellow at the Harvard Kennedy School, moderated the event.
Glovo is a three-sided marketplace composed of couriers, customers, and partners. Balancing the interests of all sides of our platform is at the core of most strategic decisions taken at Glovo. To balance those interests optimally, we need to understand quantitatively the relationship between the main KPIs that represent the interests of each side.
I recently published an article on Glovo’s Engineering blog where I explain how we used Bayesian modeling to help us tackle the modeling problems we were facing due to the inherent heterogeneity and volatility of Glovo’s operations. The example in the article talks about balancing interests on two of the three sides of our marketplace: the customer experience and courier earnings.
The skillset I developed during the Barcelona GSE Master’s in Data Science is what’s enabled me to do work like this that requires knowledge of machine learning and other fields like Bayesian statistics and optimization.
As we are approaching the COP26 meeting to be held in Glasgow later this year, a highly anticipated milestone that is to be expected is the finalization of the rulebook for Article 6 of the Paris Agreement. Article 6 calls for ‘voluntary cooperation’ between public and private actors in carbon markets and other forms of international cooperation to meet the climate goals.
Ex-ante policy modelling assessments have shown that international cooperation on carbon pricing can result in economic and environmental gains that potentially could be used to boost the ambition of the climate targets. In our OECD working paper (jointly with Sonja Peterson, Daniel Nachtigall and Jane Ellis) we present a review of the literature on ex-ante policy modelling studies that examine the economic and environmental gains that could be realised if nations cooperate on climate action. Ex-ante modelling studies usually use Computable General Equilibrium (CGE) models or Integrated Assessment Models (IAM) to understand the socio-economic and environmental impacts of climate policies. We group the research articles into the following five types of cooperative actions that could be realised between countries – carbon price harmonization, extending the coverage of carbon pricing systems, implementing a multilateral fossil fuel subsidy reform, establishing international sectoral agreements and, mitigating carbon-leakage through strategic climate coalitions and border carbon adjustment.
The literature shows that all forms of international cooperation could potentially deliver economic and environmental benefits. Extending carbon markets to include new regions would reduce the aggregate mitigation costs but would not lead to unanimous gains for each of the participating countries and thus compensation mechanisms would be needed to incentivize participation from countries that would face costs. Sectoral agreements have a limited impact but could help in the reduction of GHG emissions though not cost-effectively. All of the studies unambiguously show that removal of fossil fuel subsidies would lead to an improvement in aggregate global welfare.
Further details about the results and individual papers can be found here:
Strong Central Bank’s anti-inflationary postures are often viewed as a way to implement policies consistent with the preferences of the poor. Five examples:
Mankiw (2006): inflation “is not a tax on all assets but only on non-interest-bearing assets, such as cash. The rich are able to keep most of their wealth in forms that can avoid the inflation tax”.
FED Kansas City President, George (2017): “not as enthusiastic or encouraged as some when I see inflation moving higher,” because “inflation is a tax and those least able to afford it generally suffer the most.”
Cœuré, ECB (2012): “inflation is also particularly harmful to the poorest parts of the population”; “poorer households tend to hold a larger fraction of their financial wealth in cash, implying that both expected and unexpected increases in inflation make them even poorer.”
Central Bank of Colombia: low & stable inflation is important because “increasing inflation means a redistribution of income against the poor.”
Central Bank of Chile: inflation tends to hurt those who have a greater proportion of their wealth in money, that is, the poorest.
But do the poor prefer stronger anti-inflationary policies than the rich?
This is not obvious: anti-inflationary policies often come at the cost of less economic activity and higher unemployment rates, and these side effects of contractionary monetary policies are not necessarily evenly spread across the income distribution.
Accordingly, preferences vis-à-vis inflation versus unemployment might also not be evenly distributed across income groups. We study these relative preferences across the income distribution.
We find that:
Both the poor and the rich dislike inflation and unemployment and they both dislike extra points of unemployment more than extra points of inflation.
The aversion to unemployment relative to inflation is higher in Latin America than in Europe.
Our main point: the poor have a higher aversion to unemployment relative to inflation than the rich. This finding is at odds with the commonly held view by Central Banks that hawkish monetary policies line up with the poor’s preferences.
The idea that a compassionate Central Bank should fight inflation strongly notwithstanding the consequences on unemployment is at odds with the preferences along the income distribution estimated in our paper.
In England, domestic violence accounts for one-third of all assaults involving injury. A crucial part of tackling this abuse is risk assessment – determining what level of danger someone may be in so that they can receive the appropriate help as quickly as possible. It also helps to set priorities for police resources in responding to domestic abuse calls in times when their resources are severely constrained. In this research, we asked how we can improve on existing risk assessment, a research question that arose from discussions with policy makers who questioned the lack of systematic evidence on this.
Currently, the risk assessment is done through a standardised list of questions – the so-called DASH form (Domestic Abuse, Stalking and Harassment and Honour- Based Violence) – which consists of 27 questions that are used to categorise a case as standard, medium or high risk. The resulting DASH risk scores have limited power in predicting which cases will result in violence in the future. Following this research, we suggest that a two-part procedure would do better both in prioritising calls for service and in providing protective resources to victims with the greatest need.
In our predictive models, we use individual-level records on domestic abuse calls, crimes, victim and perpetrator data from the Greater Manchester Police to construct the criminal and domestic abuse history variables of the victim and perpetrator. We combine this with DASH questionnaire data in order to forecast reported violent recidivism for victim-perpetrator pairs. Our predictive models are random forests, which are a machine-learning method consisting of a large number of classification trees that individually classify each observation as a predicted failure or non-failure. Importantly, we take the different costs of misclassification into account. Predicting no recidivism when it actually happens (a false negative) is far worse in terms of social costs than predicting recidivism when it does not happen (a false positive). While we set the cost of incurring a false negative versus a false positive at 10:1, this is a parameter that can be adjusted by stakeholders.
We show that machine-learning methods are far more effective at assessing which victims of domestic violence are most at risk of further abuse than conventional risk assessments. The random forest model based on the criminal history variables together with the DASH responses significantly outperforms the models based on DASH alone. The negative prediction error – that is, the share of cases that would be predicted not to have violence yet violence occurs in the future – is low at 6.3% as compared with an officer’s DASH risk score alone where the negative prediction error is 11.5%. We also examine how much each feature contributes to the model performance. There is no single feature that clearly outranks all others in importance, but it is the combination of a wide variety of predictors, each contributing their own ‘insight’, which makes the model so powerful.
Following this research, we have been in discussion with police forces across the United Kingdom and policy makers working on the Domestic Abuse Bill to think how our findings could be incorporated in the response to domestic abuse. We hope this research acts as a building block to increasing the use of administrative datasets and empirical analysis to improve domestic violence prevention.
Jakob Poerschmann ’21 explains how to teach your regression the distinction between relevant outliers and irrelevant noise
Jakob Poerschmann ’21 (Data Science) has written an article called “Stop Dropping Outliers! 3 Upgrades That Prepare Your Linear Regression For The Real World” that was recently posted on Towards Data Science.
The real world example he uses to set up the piece will resonate with every fan of FC Barcelona (and probably scare them, too):
You are working as a Data Scientist for the FC Barcelona and took on the task of building a model that predicts the value increase of young talent over the next 2, 5, and 10 years. You might want to regress the value over some meaningful metrics such as the assists or goals scored. Some might now apply this standard procedure and drop the most severe outliers from the dataset. While your model might predict decently on average, it will unfortunately never understand what makes a Messi (because you dropped Messi with all the other “outliers”).
The idea of dropping or replacing outliers in regression problems comes from the fact that simple linear regression is comparably prone to extremes in the data. However, this approach would not have helped you much in your role as Barcelona’s Data Scientist. The simple message: Outliers are not always bad!
Dig into the full article to find out how to prepare your linear regression for the real world and avoid a tragedy like this one!
New research venture created by Francesco Amodio (Econ ’10), Giorgio Chiovelli (Econ ’11) and Serafín Frache
A pair of Barcelona GSE Alumni and their frequent co-author and friend have recently launched a new research centre to provide a platform for their vision of ideal research collaboration and to bring those learnings to a wider audience. This venture is Mont^2, the Montréal x Montevideo Econ Lab.
This initiative was not without its challenges despite appearing to be an easy path for a group of friends and co-authors from the outside. Its genesis happened just before the COVID-19 pandemic struck both Canada and Uruguay, where the founders are based (not to mention the rest of the world) forcing them to adapt their plans for the launch of a physical working group to an online one.
Francesco Amodio ’10 and Giorgio Chiovelli ’11 are Economics Program alumni and became firm friends after meeting as TA and student in an econometrics class. They began collaborating during their respective PhD’s, Francesco at UPF and Giorgio at Bologna in Italy. After graduating and starting their careers in Montréal and Montevideo respectively, they included a third member into their collaborative efforts, Serafín Frache, and started laying the groundwork for what would ultimately become Mont^2. Serafín had local knowledge of Uruguayan administrative data and its potential to answer exciting economic questions. From these roots, the three researchers began thinking about their long-term career plans and how they can make an impact on their communities and give back to their respective local communities and the wider academic and policy-world.
It is with this foundation that Mont^2 was created. The professors applied to Social Sciences and Humanities Research Council (SSHRC) for seed funding to utilise the unique Uruguayan data and begin building the infrastructure of Mont^2.
They also aim for the lab to structure the mentorship of the professors’ current and future pre-doctoral research assistants. This would give them the tools to work with big data and be prepared for their future careers where this skill is in demand, whether in academia or the private sector. The trio also want to bring attention to the role academic research has to play with policy-making institutions regardless of where they might be located.
Mont^2 has just been launched, but already they are hard at work on a handful of projects with RAs already enlisted. It is a working environment meant to provide a formalised structure to the growing network of researchers and collaborators that began with Francesco, Giorgio and Serafín but now stretching far beyond. The hope is for Mont^2 to strengthen their ties with policy institutions and begin to promote best practices when dealing with confidential government big data.
Is ethnic diversity good or bad for economic development? When different languages, ethnicities or races coexist in the same society, there are challenges for the economy, but also opportunities. On one hand, if individuals within ethnic groups are homogeneous, and groups differ in preferences toward policies or public goods, then conflicting preferences can lead to inefficiencies in public good provision or to policy choices that may not benefit the entire society. Inter-group tensions can also result in civil conflicts or exacerbate mistrust and lack of cooperation. However, on the other hand, if ethnic groups differ in subsistence activities or skills, then complementary specializations can generate economic gains, stimulate innovation, and promote inter-group trade. Alesina and La Ferrara (2005) provide a review of this literature. While there is a general understanding that diversity brings opportunities and challenges, there is scarce evidence on which factors determine its positive or negative consequences. When is ethnic diversity good for economic development, and when is it bad?
I ask whether the effect of ethnic diversity on economic development depends on one characteristic of ethnic groups that has received little attention: the heterogeneity of individuals within ethnic groups. Underlying previous literature is the assumption that individuals within ethnic groups tend to be homogeneous. However, individuals may differ in many dimensions, including preferences, economic activities or skills, as well as cultural, genetic, and linguistic traits. I focus on having different economic specializations and skills within the same ethnic group, and I study whether ethnic groups with more heterogeneous individuals do better in multi-ethnic societies.
Consider two ethnic groups, A and B. The two groups differ in ethnicity. In turn, ethnic group A has individuals with diverse skills due to their different economic specializations, while ethnic group B is more homogeneous (individuals from ethnic group B have similar skills). The idea is that it may be easier for individuals of ethnicity A to live and to interact in a multi-ethnic society–they come from an ethnic group that is already highly heterogeneous. They will already be used to diverse environments. They will be more familiar with having to interact with heterogeneous individuals. If you come from an ethnic group that is highly heterogeneous, in terms of skills, you may be more willing to live and to interact with other ethnicities. In this case, positive interactions, mutually beneficial exchange, between ethnic groups will become more frequent.
The 16th Century resettlement of Peruvian ethnic groups
To study this, I collect new data on a natural experiment from Peru’s colonial history. I focus on highland Peru. There, Spanish colonizers resettled native populations in the 16th century. They forced together different ethnic groups in new villages, and this happened unintentionally. Importantly, in some ethnic groups, individuals had already been living in very different ecological zones of the Andes, at different altitudes, during the pre-colonial period, before the Spanish conquest. This creates within-group heterogeneity. In some cases, individuals from the same ethnic group were very different in terms of ecological specializations and skills – the types of lands and crops that they were used to cultivate. In other ethnic groups, everyone lived in the same climate zone, at the same altitude. I am asking: did the more heterogeneous ethnic groups do better once they were resettled in multi-ethnic villages?
Firstly, I use a map of the spatial distribution of ethnic groups at the time of the Spanish conquest. It allows me to compute the distance from each village to the closest ethnic frontier and use it as a source of quasi-random variation in ethnic diversity. During the pre-colonial period, individuals from the same ethnic group were distributed vertically, at different altitudes. This is the thesis of the anthropologist John Murra. He documents this vertical settlement pattern as a subsistence strategy in an environment in which differences in elevation create a variety of ecological zones and climates. At the time of the resettlement, the mountain environment of the Andes was new to Spanish colonizers – they were used to a flatter world. As a result, in villages that were created close to ethnic borders, they concentrated individuals from different ethnicities unintentionally (Pease 1978; Wachtel 1976). Secondly, I use spatial data on the distribution of ecological zones to compute a proxy for the heterogeneity of skills within each ethnic group prior to the conquest. It is important to note that ethnic groups with more heterogeneous skills may be different in other dimensions (e.g., group size, population density, etc). In the analysis, I use all the available data on the pre-colonial characteristics of ethnic groups to account for the main correlates of within-group heterogeneity.
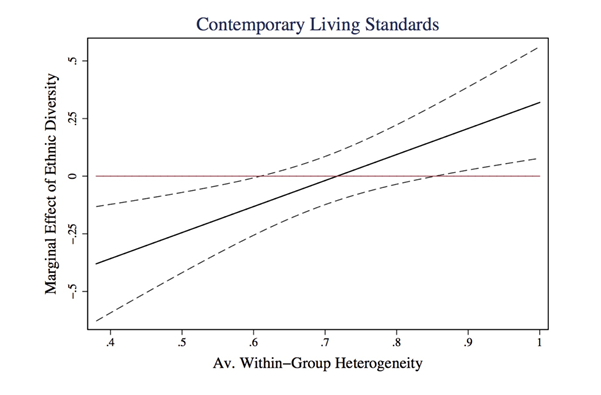
The first result in the paper documents the direct effect of ethnic diversity, which I benchmark against previous results in the literature. I find that ethnic diversity is robustly associated with lower living standards in the long run. Specifically, I explore a variety of outcomes that capture contemporary living standards. As proxies for local economic activity, I use light intensity per capita (2000-2003) and a measure of non-subsistence agriculture from the agricultural census of 1994. For access to public infrastructure, I use data from the 1993 population census on access to public sanitation and the public network of water supply. This result is in line with the literature on the costs of ethnic diversity, though it also highlights the persistent consequences of forced diversity at the local level. When examining the effect of ethnic diversity and within-group heterogeneity, I find the following pattern:
The figure shows the average effect size of ethnic diversity as a function of within-group heterogeneity. I find a robust pattern: the more heterogeneous an ethnic group was prior to resettlement, the lower the cost of ethnic diversity. On average, where ethnic groups have more heterogeneous individuals in terms of skills, the negative effect of ethnic diversity is reduced, and ethnic diversity may even become an advantage for economic development. To understand the evolution of these long-term effects, I use data from the 1876 population census on occupations and literacy rates, showing that the documented pattern persists over time.
Why is this happening? When exploring potential channels, I find evidence consistent with cultural transmission. Individuals from more heterogeneous ethnic groups in terms of skills are more likely to interact with other ethnicities. Using data from colonial records, I find evidence suggesting cooperative behavior and more open attitudes when interacting with other ethnic groups. Overall, understanding whether individuals from more heterogeneous ethnic groups are better able to integrate in a multi-ethnic society is a relevant question, not only in an increasingly globalized world, but also in the context of forced displacements and migrations, like in the case of refugees.
References
Alesina, A., and La Ferrara, E. (2005). “Ethnic Diversity and Economic Performance.” Journal of Economic Literature, 43 (3), pp. 762-800.
Murra, J. V. (1975). Formaciones económicas y políticas del mundo andino. Instituto de Estudios Peruanos.
Pease, F. G. Y. (1978). Del Tawantinsuyu a la historia del Perú, Instituto de Estudios Peruanos.
Wachtel, N. (1976). Los vencidos: los indios del Perú frente a la conquista española (1530-1570). Alianza.
We use our own and third party cookies to carry out analysis and measurement of our website activities, in order to improve our services. Your continuing on this website implies your acceptance of these terms.