Editor’s note: This post is part of a series showcasing BSE master projects. The project is a required component of all Master’s programs at the Barcelona School of Economics.
Abstract
Vector autoregression (VAR) models are a popular choice for forecasting of macroeconomic time series data. Due to their simplicity and success at modelling the monetary economic indicators VARs have become a standard tool for central bankers to construct economic forecasts. Impulse response functions can be readily retrieved and are used extensively to investigate the monetary transmission mechanism. In light of the recent advancements in computational power and the development of advanced machine learning and deep learning algorithms we propose a simple way to integrate these tools into the VAR framework.
This paper aims to contribute to the time series literature by introducing a ground-breaking methodology which we refer to as DeepVector Autoregression (Deep VAR). By fitting each equation of the VAR system with a deep neural network, the Deep VAR outperforms the VAR in terms of in-sample fit, out-of-sample fit and point forecasting accuracy. In particular, we find that the Deep VAR is able to better capture the structural economic changes during periods of uncertainty and recession.
Conclusions
To assess the modelling performance of Deep VARs compared to linear VARs we investigate a sample of monthly US economic data in the period 1959-2021. In particular, we look at variables typically analysed in the context of the monetary transmission mechanism including output, inflation, interest rates and unemployment.
Our empirical findings show a consistent and significant improvement in modelling performance associated with Deep VARs. Specifically, our proposed Deep VAR produces much lower cumulative loss measures than the VAR over the entire period and for all of the analysed time series. The improvements in modelling performance are particularly striking during subsample periods of economic downturn and uncertainty. This appears to confirm or initial hypothesis that by modelling time series through Deep VARs it is possible to capture complex, non-linear dependencies that seem to characterize periods of structural economic change.
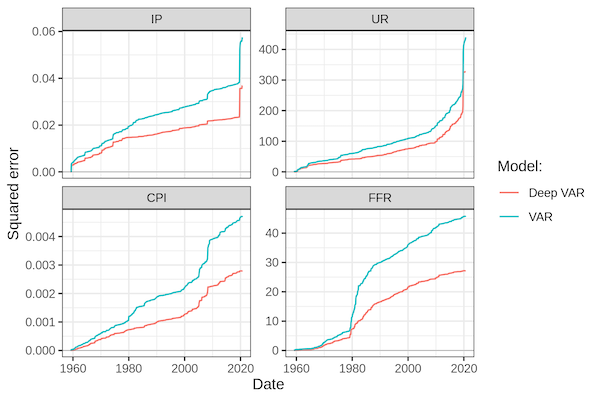
When it comes to the out-of-sample performance, a priori it may seem that the Deep VAR is prone to overfitting, since it is much less parsimonious that the conventional VAR. On the contrary, we find that by using default hyperparameters the Deep VAR clearly dominates the conventional VAR in terms of out-of-sample prediction and forecast errors. An exercise in hyperparameter tuning shows that its out-of-sample performance can be further improved by appropriate regularization through adequate dropout rates and appropriate choices for the width and depth of the neural. Interestingly, we also find that the Deep VAR actually benefits from very high lag order choices at which the conventional VAR is prone to overfitting.
In summary, we provide solid evidence that the introduction of deep learning into the VAR framework can be expected to lead to a significant boost in overall modelling performance. We therefore conclude that time series econometrics as an academic discipline can draw substantial benefits from further work on introducing machine learning and deep learning into its tool kit.
We also point out a number of shortcomings of our paper and proposed Deep VAR framework, which we believe can be alleviated through future research. Firstly, policy-makers are typically concerned with uncertainty quantification, inference and overall model interpretability. Future research on Deep VARs should therefore address the estimation of confidence intervals, impulse response functions as well as variance decompositions typically analysed in the context of VAR models. We point to a number of possible avenues, most notably Monte Carlo dropout and a Bayesian approach to modelling deep neural networks. Secondly, in our initial paper we benchmarked the Deep VAR only against the conventional VAR. In future work we will introduce other non-linear approaches to allow for a fairer comparison.
Code
To facilitate further research on Deep VAR, we also contribute a companion R package deepvars that can be installed from GitHub. We aim to continue working on the package as we develop our research further and want to ultimately move it onto CRAN. For any package related questions feel free to contact Patrick, who authored and maintains the package. The is also a paper specific GitHub repository that uses the deepvars package.
Connect with the authors
- Marc Agustí ’21
- Patrick Altmeyer ’21 (also @paltmey on Twitter and @pat-alt on GitHub)
- Ignacio Vidal-Quadras Costa ’21