Finance master project by Lapo Bini and Daniel Mueck ’21
Editor’s note: This post is part of a series showcasing BSE master projects. The project is a required component of all Master’s programs at the Barcelona School of Economics.
Abstract
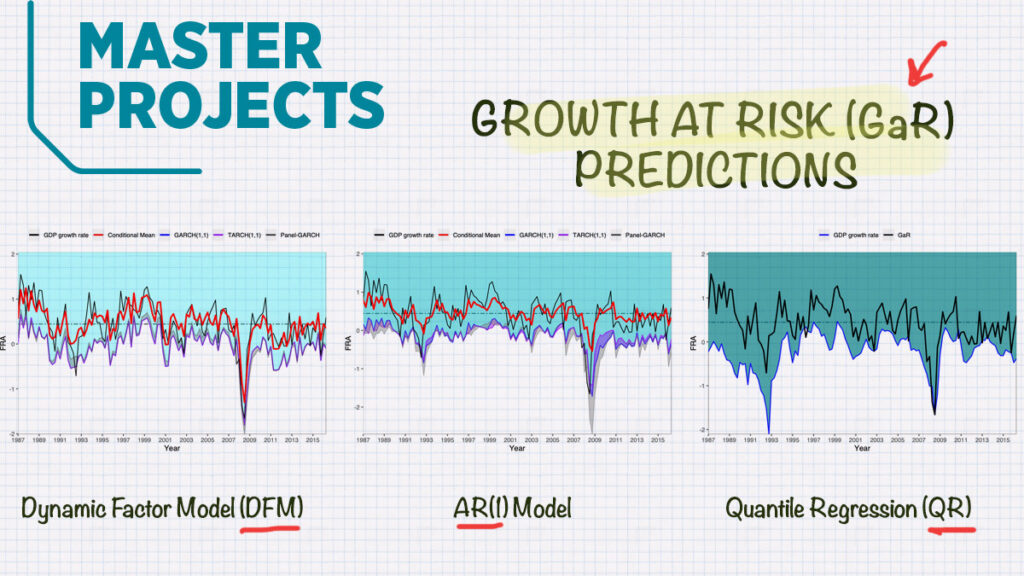
In order to analyse whether financial conditions are relevant downside risk predictors for the 5% Growth at Risk conditional quantile, we propose a Dynamic Factor- GARCH Model, comparing it to the two most relevant approaches in the literature. We conduct an out-of sample forecasting analysis on the whole sample, as well as focusing on a period of increased European integration after the 2000s. Always, including the national financial conditions index, term structure and housing prices for 17 European countries and the United States, as down side risk predictors. We find evidence of significant predicting power of financial conditions, which, if exploited correctly, becomes more relevant in times of extraordinary financial distress.
Conclusions
We propose a Dynamic Factor-GARCH model which computes the conditional distribution of the GDP growth rates non-parametrically, exploiting the dimensions of a panel of national financial conditions and compare it to the models of Adrian, Boyarchenko, and Giannone (2016 )and Brownlees and Souza (2021) out-of-sample.
Contrasting to our in-sample results, the out-of sample results exhibit a higher degree of heterogeneity across countries. While our model performs at least as good or better as the AR(1)-GARCH(1,1) specification of Brownlees and Souza (2021) in the long run, it produces unsatisfactory results for the one-step forecast horizon.
However, by focusing our out-of-sample analysis on a smaller sample around the period of the Great Recession, we not only outperform the other two models analysed, but also obtain strong indication of increased importance and predictive power of financial conditions.
We provide evidence that by correctly modelling financial conditions, they not only exhibit predictive ability for GDP downside risk, but also improve in-sample GaR predictions. Further, we show that they are relevant out-of-sample predictors in the long run. Finally, when focusing on periods of extraordinary financial distress, like the Great Recession, financial conditions become even more relevant. However, the right model needs to be applied in order to exploit that predictive power.
Explained intuitively by Patrick Altmeyer (Finance ’18, Data Science ’21) through a tale of cats and dogs
Is artificial intelligence (AI) trustworthy? If, like me, you have recently been gobsmacked by the Netflix documentary Coded Bias, then you were probably quick to answer that question with a definite “no”. The show documents the efforts of a group of researchers headed by Joy Buolamwini, that aims to inform the public about the dangers of AI.
One particular place where AI has already wreaked havoc is automated decision making. While automation is intended to liberate decision making processes of human biases and judgment error, it all too often simply encodes these flaws, which at times leads to systematic discrimination of individuals. In the eyes of Cathy O’Neil, another researcher appearing on Coded Bias, this is even more problematic than discrimation through human decision makers because “You cannot appeal to [algorithms]. They do not listen. Nor do they bend.” What Cathy is referring to here is the fact that individuals who are at the mercy of automated decision making systems usually lack the necessary means to challenge the outcome that the system has determined for them.
In my recent post on Towards Data Science, I look at a novel algorithmic solution to this problem. The post is based primarily on a paper by Joshi et al. (2019) in which the authors develop a simple, but ingenious idea: instead of concerning ourselves with interpretability of black-box decision making systems (DMS), how about just providing individuals with actionable recourse to revise undesirable outcomes? Suppose for example that you have been rejected from your dream job, because an automated DMS has decided that you do not meet the shortlisting criteria for the position. Instead of receiving a standard rejection email, would it not be more helpful to be provided with a tailored set of actions you can take in order to be more successful on your next attempt?
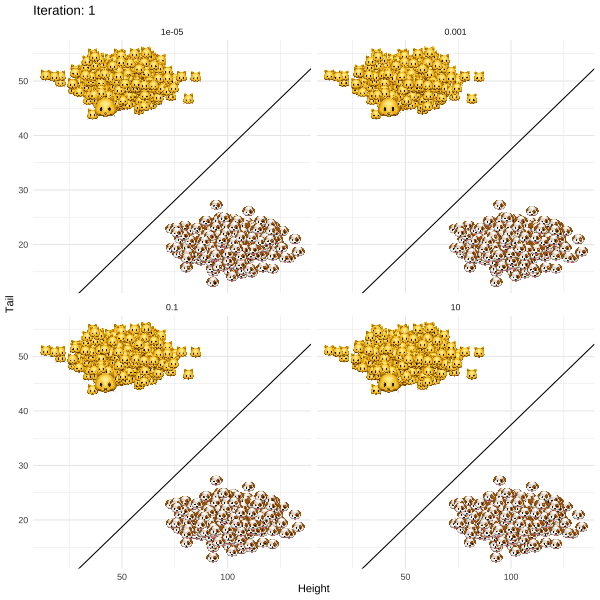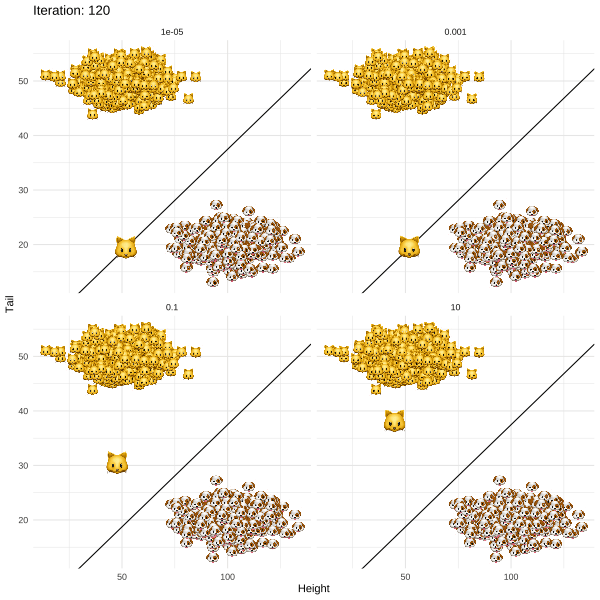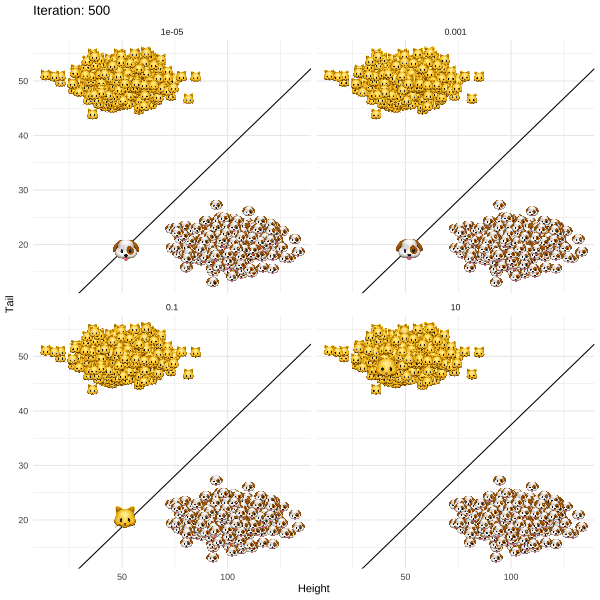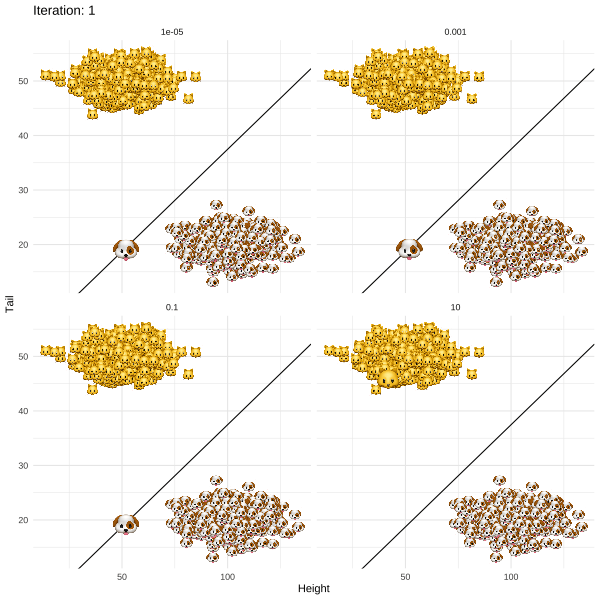
The methodology proposed by Joshi et al. (2019) and termed REVISE is an attempt to put this idea into practice. For my post I chose a more light-hearted topic than job rejections to illustrate the approach. In particular, I demonstrate how REVISE can be used to provide individual recourse to Kitty 🐱, a young cat that identifies as a dog. Based on information about her long tail and short overall height, a linear classifier has decided to label Kitty as a cat along with all the other cats that share similar attributes (Figure below). REVISE sends Kitty on the shortest possible route to being classified as a dog 🐶 . She just needs to grow a few inches and fold up her tail (Figure below).
The following summary should give you some flavour of how the algorithm works:
Initialise x, that is the attributes that will be revised recursively. Kitty’s original attributes seem like a reasonable place to start.
Through gradient descent recursively revise x until g(x*)=🐶. At this point the descent terminates since for these revised attributes the classifier labels Kitty as a dog.
Return x*-x, that is the individual recourse for Kitty.
The simplified REVISE algorithm in action: how Kitty crosses the decision boundary by changing her attributes. Regularisation with respect to the distance penalty increases from top left to bottom right. Image by author.
This illustrative example is of course a bit silly and should not detract from the fact that the potential real-world use cases of the algorithm are serious and reach many domains. The work by Joshi et al. adds to a growing body of literature that aims to make AI more trustworthy and transparent. This will be decisive in applications of AI to domains like Economics, Finance and Public Policy, where decision makers and individuals rightfully insist on model interpretability and explainability.
Further reading
The article was featured on TDS’ Editor’s Picks and has been added to their Model Interpretability column. This link takes you straight to the publication. Readers with an appetite for technical details around the implementation of stochastic gradient descent and the REVISE algorithm in R may also want to have a look at the original publication on my personal blog.
Connect with the author
Following his first Master’s at Barcelona GSE (Finance Program), Patrick Altmeyer worked as an economist for the Bank of England for two years. He is currently finishing up the Master’s in Data Science at Barcelona GSE.
Upon graduation Patrick will remain in academia to pursue a PhD in Trustworthy Artificial Intelligence at Delft University of Technology.
Finance master project by Güneykan Özkaya and Yaping Wang ’20
Editor’s note: This post is part of a series showcasing BSE master projects. The project is a required component of all Master’s programs at the Barcelona School of Economics.
Introduction
Historically, there have been many strategies implemented to solve the portfolio choice problem. An accurate estimation of optimal portfolio allocation is challenging due to the non-deterministic complexities of financial markets. Due to this complexity, investors tend to resort to the mean-variance framework. If we consider the mean-variance framework, there are several drawbacks to this approach. The most pivotal one could be normality assumption on returns so that we could depict the behavior of returns only by mean and variance. However, it is well known that returns possess a heavy-tailed and skewed distribution, which results in underestimated risk or overestimated returns.
In this paper, we rely on a distribution of different metrics other than returns to optimize our portfolio. In simple terms, we combine several parametric and non-parametric bandit algorithms with our prior knowledge that we obtain from historical data. This framework gives us a decision function in which we can choose portfolios to include in our final portfolio. Once we have our candidate portfolio weights, we apply the first-order condition over portfolio variances to distribute our wealth between 2 candidate set of portfolio weights such that it minimizes the variance of the final portfolio.
Our results show that if contextual bandit algorithms applied to portfolio choice problem, given enough context information about the financial environment, they can consistently obtain higher Sharpe ratios compared to classical methodologies, which translates to a fully automated portfolio allocation framework.
Key results
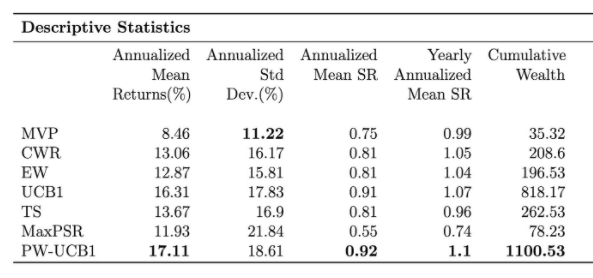
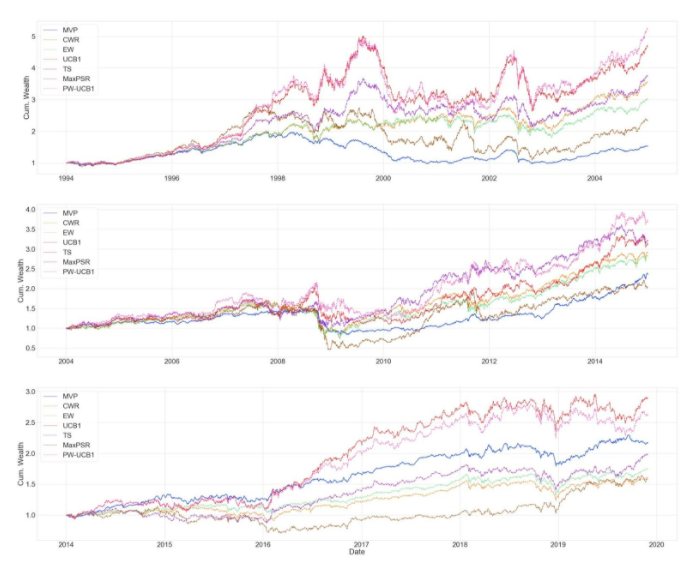
We conduct the experiments on 48 US value-weighted industry portfolios and consider the time range 1974-02 to 2019-12; The table below reports extensive evaluation criteria of following strategies by order; Minimum Variance Portfolio (MVP), Constant Weight Rebalance portfolio (CWR), Equal Weight portfolio (EW), Upper Confidence Bound 1 (UCB1), Thompson Sampling (TS), Maximum Probabilistic Sharpe ratio (MaxPSR), Probability Weighted UCB1 (PW-UCB1). Below the table, one can observe the evaluation of cumulative wealth through the whole investment period.
Table 1. Evaluation Metrics
One thing to observe here, even UCB1 and PW-UCB yield the highest Sharpe ratios. They also have the highest standard deviation, which implies bandit portfolios tend to take more risk than methodologies that aim to minimize variance, but this was already expected due to the exploration component. Our purpose was to see if the bandit strategy can increase the return such that it offsets the increase in standard deviation. Thompson sampling yields a lower standard deviation because TS also consists of portfolio strategies that aim to minimize variance in its action set.
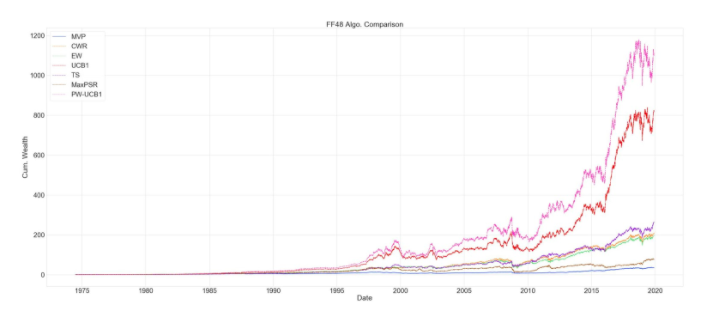
Figure 1. Algorithm Comparison
We also include the evaluation of cumulative wealth throughout the whole period and in 10 year time intervals. One interesting thing to notice is that bandit algorithms’ performance diminishes during periods of high momentum followed by turmoil. The drop in the bandit algorithms’ cumulative wealth is more severe compared to classic allocation strategies such as EW or MVP. Especially PW-UCB1, this also can be seen from standard deviation of the returns. This is due to using the rolling window to estimate moments of the return distribution. Since we are weighing UCB1 with the Sharpe ratio probability, and since this probability reflects the 120-day window, algorithm puts more weights on industries that gain more during high momentum periods, such as technology portfolio. During the dot.com bubble (1995-2002) period, UCB1 and PW-UCB1 gain a lot by putting more weight on technology portfolio, but they suffer the most, during the turmoil that followed high momentum period. One can solve this issue by using more sophisticated prediction model to estimate returns and the covariance matrix.
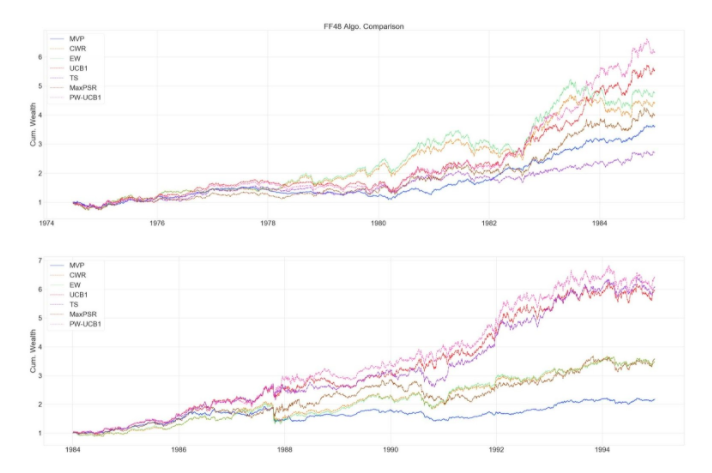
Figure 2. 1974-1994 Algorithm Comparison
Figure 3. 1994-2020 Algorithm Comparison
To conclude, our algorithm allows dynamic asset allocation with the relaxation of strict normality assumption on returns and incorporates Sharpe ratio probability to better evaluate performances. Our algorithm could appropriately balance the benefits and risks well and achieve higher returns by controlling risk when the market is stable.
Editor’s note: This post is part of a series showcasing BSE master projects. The project is a required component of all Master’s programs at the Barcelona School of Economics.
Introduction
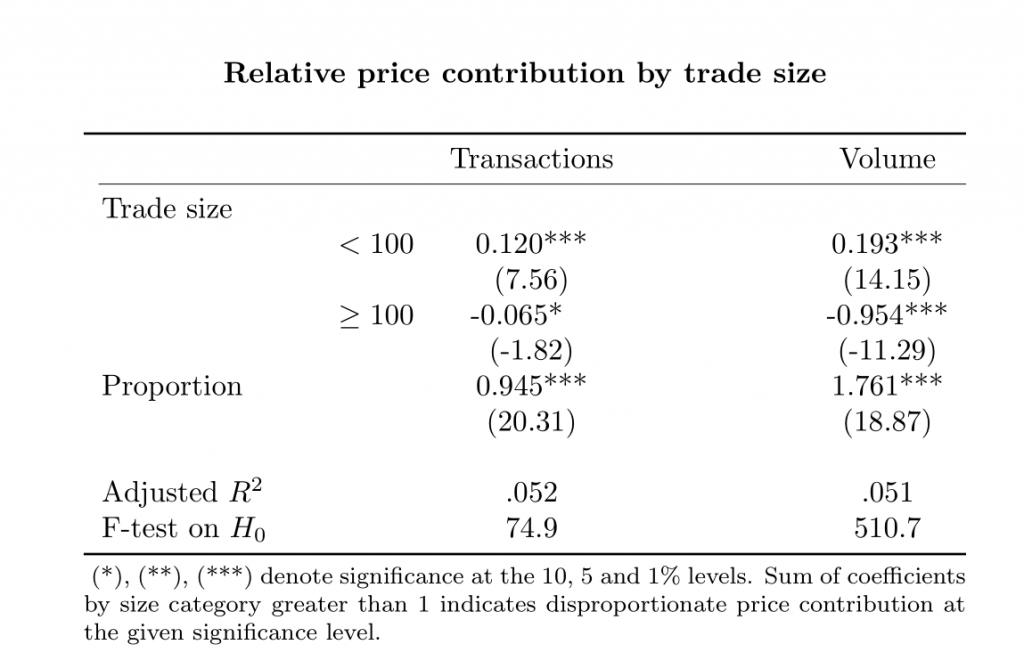
This paper builds on the stealth trading literature to investigate the relationship between several different trade characteristics and price discovery in US equity markets. Our work extends the Weighted Price Contribution (WPC) methodology, which in its simplest form posits that if all trades conveyed the same amount of information, their contribution to market price dynamics over a certain time interval should equate their share in total transactions or total volume traded in the period considered. Traditionally, the approach has been used to provide evidence that trades of smaller sizes convey a disproportionate amount of information in mature equity markets through the estimation of a parsimonious linear specification.
The methodology is flexible enough to accommodate for a first set of key extensions in our work, which focus on studying the relative price contribution from trades initiated by high-frequency traders (HFTs) and on stocks of different market capitalization categories over the daily session. Nonetheless, previous research has found that short-lived frictions make the WPC methodology ill-suited for analyzing price discovery at under-a-minute frequencies, a key timespan when HFTs are in focus. Therefore, to analyze the information content of trades of different attributes at higher frequencies we use a Fixed Effects specification to characterize trades that correctly anticipate price trends over under-a-minute windows of varying length as price informative.
Key results
At the daily level, our results underpin prior research that has found statistical evidence of smaller trades inputting a disproportionate amount of information into market prices. This result holds regardless of the type of initiating trader or market capitalization category of the stock being transacted, suggesting that the type of trader on either side on the transaction does not significantly alter the average information content over the session.
At higher frequencies, trades initiated by HFTs are found to contribute more to price discovery than trades initiated by non-HFTs only when large and mid cap stocks are being traded, consistent with prior empirical findings pointing to HFTs having a strong preference for trading on highly liquid stocks.
Editor’s note: This post is part of a series showcasing BSE master projects. The project is a required component of all Master’s programs at the Barcelona School of Economics.
Paper abstract
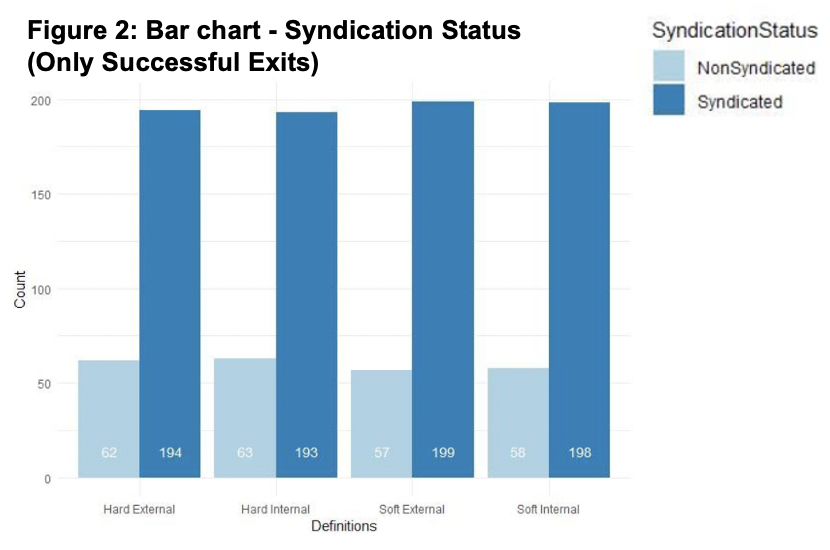
In venture capital, two or more venture capitalists (VC) often form syndicates to participate in the same financing rounds. Historically, syndicated investments have been found to have a positive effect on the investment performance. The paper provides insight into the effects of syndication on the likelihood of a successful exit for the venture-backed firm. It addresses the possible driving components such as the composition of the syndicates and, in particular, the internal investment funds being classed as external firms in two of the four models proposed, as well as a relaxation on the definition of investment round. One of the main conclusions is that in the analysis, using the chance of exiting and money in minus money out as success factors, syndication coefficients across all models are shown to have a higher chance of exiting. This supports the Value-add hypothesis and opposes the alternative, the Selection hypothesis, as it proposes that syndicated VC firms bring varying expertise to the project in order to increase the success factors post-investment. The paper advises to proceed with caution as the story is not consistent across the analysis.
Main conclusions
The paper aimed at looking to add to the literature of debates on reasons for syndication, such as the Valueadd vs Selection hypothesis as set out from various points of views. Uncertainty around profitability is the reason for syndication through the Selection hypothesis, however, the Value-add hypothesis suggests that VCs syndicate to add additional value to the venture post-investment. This is where the varying definitions of syndication we introduced, in order to draw inferences from the data. If the Soft definition of syndication (where syndication can occur across multiple investment rounds), was more successful, it may favour the Value-add hypothesis. However, in the initial test using “exited” as success, the Soft syndication models did not show a significant difference compared to the Hard syndication models.
Using the chance of exiting as a success factor, syndication coefficients across all models showed a higher chance of exiting. Using this as a success factor, you could argue for the Value-add and against the Selection hypothesis, as syndicated investments across all models resulted in a higher chance of exiting the investment. Including the key controls, resulted in similar conclusions to be drawn, with syndication increasing the log odds of exiting. This does support the conclusions of Brander, Amit and Antweiler (2002) that highlight that the Valueadd hypothesis dominates.
Using Money Out minus Money In as a success factor it was shown syndicated investments increased this which would be in line with the Value-add hypothesis according to Brander, Amit and Antweiler (2002), however, this could be down to successful companies being input with greater investments which are already successful.
Using exit duration as a success factor, conclusions were unable to be drawn about syndication, as the syndication coefficients were not significant. A potential reason for this, as the literature suggests, Guo, Lou and Pérez-Castrillo (2015), highlight, that the type of fund the investment is being purchased for has an impact on the duration and amount of funding, therefore impacting the returns of the VCs. They find that CVC (corporate venture capital) backed startups receive a significantly higher investment amount and stay in the market for longer before they exit (Guo, Lou and Pérez-Castrillo, 2015). The data did not allow us to analyse the type of fund, meaning the investment strategy could differ from the outset. As no control variable exists for the type of fund it is therefore assumed this does not significantly impact the outcome. Controlling for the type of fund may have shed light on this aspect of the results.
ADBI Working Paper by Finance ’18 alumni Lavinia Franco, Ana Laura García, Vigor Husetović, and Jes Lassiter
A master project by four alumni of the Finance Program Class of 2018 is soon to be added to the working paper series of the Asian Development Bank Institute (ADBI).
Abstract
Fintech has increasingly become part of the global economy with the evolution of technology, increasing investments in fintech firms, and greater integration between traditional incumbent financial firms and fintech. Since the 2007–2009 financial crisis, research has also paid more attention to systemic risk and the impact of financial institutions on systemic risk. As fintech grows, so too should the concern about its possible impact on systemic risk. This paper analyzes two indices of public fintech firms (one for the United States and another for Europe) by computing the ∆CoVaR of the fintech firms against the financial system to measure their impact on systemic risk. Our results show that at this time fintech firms do not contribute greatly to systemic risk.
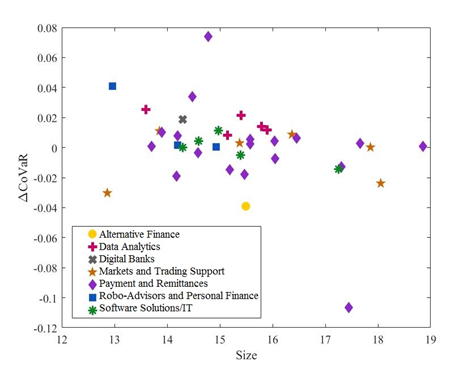
Figure B.2: US Fintech: ∆CoVaR and Size
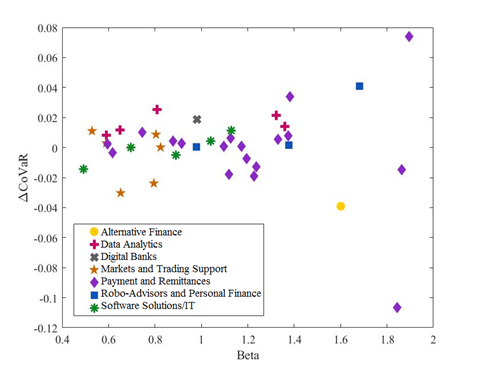
Figure B.3: US Fintech: ∆CoVaR and Beta
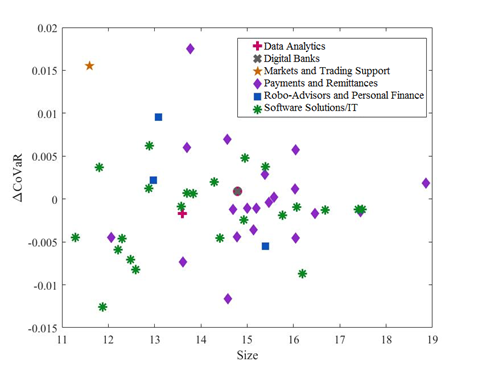
Figure B.4: European Fintech: ∆CoVaR and Size
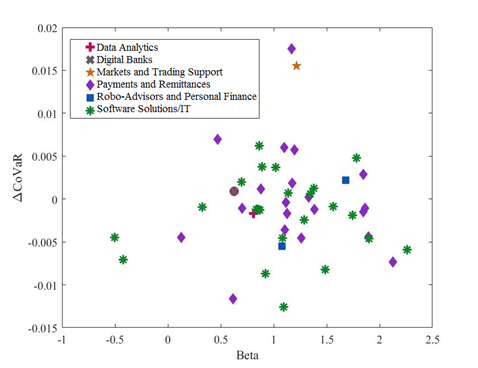
Figure B.5: European Fintech: ∆CoVaR and Beta
Conclusions and key results
Our results show that, for the US, the payment and remittances and the market and trading support categories contribute the most to the VaR of the fintech industry. Instead, in Europe, fintech firms that provide software solutions and information technologies seem to be contributing the most to the risk of the sector. The estimation that includes fintech firms and the representative sample of the financial sectors show that fintech firms are not systemically important. Within the US financial system, the fintech companies that do contribute to systemic risk increase it by around 0.03%, while, in Europe, fintech firms contribute very little to the systemic impact (close to 0%). The Spearman’s rank correlation between a fintech firm’s ∆CoVaR and its respective size and between a fintech firm’s ∆CoVaR and its beta strengthens the importance of our estimations for a better assessment of systemic risk rather than just relying on the size and the beta of the firms to determine their likely contribution to systemic risk.
Some limitations of our study include the scope of our analysis method (∆CoVaR), the representation of the fintech sector, and the analysis of only two markets. However, micro-level data analysis focusing on each individual fintech category and changing the focus on emerging markets could reveal the specific risks, highlighting key research lines.
Jebb Peria ’10 (Finance), Associate at EV Private Equity
Jebb Peria ’10 recently answered some questions about careers in private equity in a post for his employer, EV Private Equity. Here are a few excerpts from the interview.
I’ve heard of private equity but how does it differ from, say, venture capital or fund management?
Fund management is basically a firm of money managers investing pooled funds from investors. The capital may be invested in traditional asset classes such as equities, fixed income and cash and alternative asset classes such as hedge funds, private equity, real estate, commodities and infrastructure.
Private Equity (PE) is an active form of investment in privately held companies with the objective of growing them over a medium to long-term period. As active investors, PE firms work closely with management to increase and maximise the company’s value through financial engineering, improved governance and operational performance.
At EV Private Equity, we primarily invest in early-growth companies that have: a distinct product or service; the potential to grow rapidly; low levels of debt; and experienced management teams. We seek innovative and disruptive technology companies that can scale and drive superior returns.
Venture Capital (VC) is a subset of PE which provides capital to early-stage businesses, usually in technology-based sectors. Venture capitalists normally invest in high-growth, high-risk, start-up or early-staged ventures, typically with a bias towards technology or innovation. PE tends to focus on later-stage investment in businesses that are more established and are generating cash. VC uses primarily equity while PE may use equity and debt (leverage).
Both PE and VC use a measurement known as MOIC (Multiple On Invested Capital) to calculate the returns they make from their investments. PE target returns range from 2x-5x while VC returns are expected to be higher.
Do I need an MBA from Harvard, a mathematics degree or an accountancy qualification in order to be considered?
No, not necessarily. As a matter of fact, I don’t have any of those credentials. I graduated with a BA in Economics (with highest distinction) from York University in Canada, an MA in Economics from the University of Toronto, and an MSc in Finance from Barcelona GSE. I am also a CFA® charterholder. I guess this depends on which type of PE firm you want to work with as there are generalists and specialists.
As energy specialists, our team at EV Private Equity is comprised of people with substantial experience in the energy industry [oil and gas (O&G), oil field services (OFS)] as well as those from technical disciplines (reservoir, drilling, mechanical, chemical, and software engineering as well as geophysics and naval architecture). We also recruit candidates with graduate business degrees in areas such as MBA, finance, economics, strategy etc.
Is it true that private equity is very secretive and is not accountable to any regulators or governments?
False.
EV Private Equity is regulated by the Financial Conduct Authority in the UK and the SEC in the US under the Investment Advisor Act of 1940.
Like any other firm, EV Private Equity and its portfolio companies are obliged to abide by the laws and regulations of all countries we operate in. This is also part of the fiduciary duty towards the firm’s institutional investors, comprised mainly of large public and private pension funds, insurance companies, university endowment funds and sovereign wealth funds.
What is a typical day like in private equity?
I typically start the morning reading through the latest news and market trends. I skim-through DagensNæringsliv, Bloomberg, Financial Times and even LinkedIn to check on the latest oil price, mergers and acquisitions (M&As) and geopolitical news. Then, I read through my emails to check for any updates on the portfolio companies I’m involved with and any immediate requests from the partners.
My day is normally split between fixed deliveries and ad hoc tasks. My deliveries would range from weekly meetings and operational updates with portfolio companies to monthly, quarterly and yearly financial reporting to updating fair market values of portfolio companies to weekly meetings with the digital marketing team. I would also participate in quarterly investor meetings, board meetings as well as annual strategy meetings with my portfolio companies.
If there’s a deal I am involved in, I would build the financial model, perform valuation and sensitivity analysis and support the drafting of the investment paper. I would also be participating in weekly call updates with the due diligence providers regarding any red flags and show stoppers (in other words, developments that may affect our decision to invest).
If one of my portfolio companies is preparing for an exit, I might be having calls with the management and the financial advisors discussing the potential buyers, the market sentiment and the status of the Information Memorandum (IM), the document we share with prospective buyers.
There is not much slack time. If I do have some spare time, I can always find something to work on: a process to simplify and make more efficient; a model to automate; improvements to our social media presence; or offering support to other office locations.
What are the rewards?
Helping to create value for the company and produce superior returns for investors is rewarding and gratifying.
I also get to work with different partners, management teams, board members and technologies. These teach me different insights, strategies, and management styles.
It is very rewarding to work with the smart, entrepreneurial and down-to-earth group of individuals at EV Private Equity. They make the workplace fun and invigorating.
Of course, the job is also financially rewarding. I would like to believe that I am fairly and reasonably remunerated given my performance and contributions, the skillset I bring to the table, and my dedication to my craft.
Finance master project by Daniel A. Landau and Gabriel L. Ramos ’19
Editor’s note: This post is part of a series showcasing BSE master projects. The project is a required component of all Master’s programs at the Barcelona School of Economics.
Abstract
In this paper, we characterize a variety of international financial markets as partially correlated networks of stock returns via the implementation of the joint sparse regression estimation techniques of Peng et al. (2009). We explore a number of mean-variance portfolios, with the aim of enhancing out-of-sample portfolio performance by uncovering the hidden network dynamics of optimal portfolio allocation. We find that Markowitz portfolios generally dissuade the inclusion of central stocks in the network, yet the interaction of a stock’s individual and systemic performance is more complex. This motivates us to explore the time-varying correlation of these topological features, which we find are highly market dependent. Building on the work of Peralta & Zareei (2016), we implement a number of investment strategies aimed at simplifying the portfolio selection process by allocating wealth to a targeted subset of stocks, contingent on the time-varying network dynamics. We find that applying mean-variance allocation to a restricted sample of stocks with daily portfolio re-balancing can statistically significantly enhance out-of-sample portfolio performance in comparison to a market benchmark. We also find evidence that such portfolios are more resilient during periods of major macroeconomic instability, with the results applicable to both developed and emerging markets.
Conclusion and Future Research
In our work, we represent 4 international exchanges as individual networks of partially correlated stock returns. To do so, we build a Graph, comprised of a set of Vertices and Edges, via the implementation of the joint sparse regression estimation techniques of Peng et. al (2009). This approach allows us to uncover some of the hidden topological features of a series of Markowitz tangency portfolios. We generally find that investing according to MPT dissuades the inclusion of highly central stocks in an optimally designed portfolio, hence keeping portfolio variances under control. We find that this result is market-dependent and more prevalent for certain countries than for others. From this cross-sectional network analysis, we learn that the interaction between a stock’s individual performance (Sharpe ratio) and systemic performance (eigenvector centrality) can be complex. This motivates us to explore the time-varying correlation ρ between Sharpe ratio and eigencentrality.
Optimal Weights for Tangency Portfolio Strategy.
Overall, we show that in considering the time-varying nature of partially correlated networks, we can enhance out-of-sample performance by simplifying the portfolio selection process and investing in a targeted subset of stocks. We also find that our work proposes a number of future research questions. Although we implement short-sale constraints, it would also be wise to introduce limits on the amount of wealth that can go into purchasing stocks, as this would help to avoid large portfolio variances. Furthermore, our work paves the way for future research into the ability of ρ-dependent investment strategies to enhance portfolio performance in times of macroeconomic distress and major financial crises.
Master project by Patrick Altmeyer, Jacob Daniel Grapendal, Makar Pravosud, and Gand Derry Quintana ’18
Editor’s note: This post is part of a series showcasing Barcelona GSE master projects by students in the Class of 2018. The project is a required component of every master program.
There exists a substantial body of literature concerned with the calibration of the Heston model for pricing financial derivatives under stochastic volatility, many of which rely on computationally expensive algorithms. Our paper evaluates a calibration method of the Heston model proposed by Alòs, De Santiago, and Vives (2015), which can be used to price derivatives with little computational effort. The calibration method is innovative in the sense that it considers only the three most critical regions of the implied volatility surface. The regions where the underlying option is, firstly, at-the-money, secondly, close to maturity and lastly, far away from maturity. Although their procedure is parsimonious and very easy to implement, they calibrate a model whose empirical applicability is contested.
The main contribution of our paper is the evaluation of their model in an extensive numerical exercise as well as an application to real data. Collecting empirical option data has been one of the main challenges with respect to this work, since historical data on financial derivatives is not accessible to the public. Faced with this issue we have written a script that allowed us to automatically scrape option data at a high frequency over just a couple of weeks. Thus, we build our own extensive data base. Also, we have made the data and code available on https://griipen.shinyapps.io/bgse/ and https://github.com/HitKnit/BGSE2018/tree/HitKnit-optionscraping, respectively.
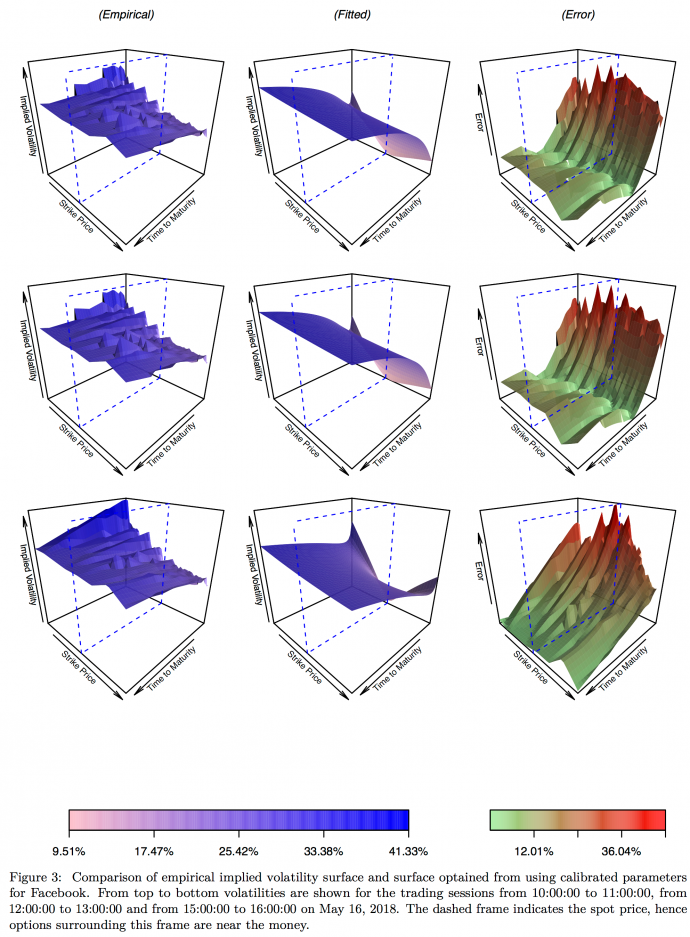
In terms of our results, we find that whilst the calibration method has solid theoretical foundations and produces satisfactory estimation results within the theoretical Heston universe. However, it fails in practice. Specifically, for the numerical exercise we find that out of all simulations the maximum average error across the entire volatility surface is 0.999 percent while the mean error across simulations is only 0.481 percent. In sharp contrast to that, absolute percentage errors for our empirical data are on the order of 30-40 percent in many cases. In the following figure, we present our findings for intra-daily data from May 16, 2018. The left column shows empirical implied volatilities for a European call option on Facebook Inc. (FB) stocks. From top to bottom volatilities are shown for the opening, lunch and closing sessions. The central column shows the fitted volatility surfaces while the right column shows absolute percentage differences between empirical and estimated values. The finding that errors are particularly high for at-the-money options with short times to maturity is robust across the entire data sample.
Conclusions and key results:
In light of these results, we conclude that inherent limitations of the Heston Model disqualify the calibration for practical use. Nonetheless, we believe that similarly simple calibration methods as the one examined here should be used in combination with more sophisticated option pricing models.
Ricard Murillo, Marta Guasch, and Mar Domènech in front of Caixabank. Photo by Marta Guasch.
We’ve just come across some articles written by several Barcelona GSE Alumni who are now Research Assistants and Economists at Caixabank Research in Barcelona. New articles are published each month on a range of topics.
Below is a list of all the alumni we found listed as article contributors, as well as their most recent publications in English (click each author to view his or her full list of articles in English, Catalan, and Spanish).
If you’re an alum and you’re also writing about Economics, let us know where we can find your stuff!
Gerard Arqué (Master’s in Macroeconomic Policy and Financial Markets ’09)
We use our own and third party cookies to carry out analysis and measurement of our website activities, in order to improve our services. Your continuing on this website implies your acceptance of these terms.