Editor’s note: This post is part of a series showcasing BSE master projects. The project is a required component of all Master’s programs at the Barcelona School of Economics.
Abstract
The purpose of this paper is to examine aggregate and cross-sector allocations of foreign aid flows in the aftermath of epidemics and to determine whether latent effects can be observed in the following year.
Using data from the Organization for Economic Cooperation and Development (OECD) on Bilateral commitments of Official Development Assistance (ODA) from 2005-2019, we employ an Ordinary Least Squares (OLS) model based on the structural gravity framework to account for spatial interactions between donor and recipient countries.
Our results show that epidemics have a positive and significant effect on bilateral foreign aid across all sectors and that aid to the Humanitarian sector is less conditional on pre-existing relationships than others. Results for latent effects on aid vary by sector.
We further find that isolating epidemics in our analysis suggests that certain diseases prompt a different aid response wherein aid to non-health sectors falls.
Conclusions
We find that epidemics do indeed engender changes in foreign aid behavior.
To be specific, epidemics have a positive and significant effect on foreign aid commitments to all sectors. Our results are unable to shed light on the hypothesis of reallocation between sectors. However, they do illustrate that aid to both health-related and non-health-related sectors increases.
Aid in this context is also persistent. That is, our results, robust to numerous checks, show that the positive effects of epidemics may be observed not only in the year of the outbreak but also in the following year.
By analyzing each disease independently, we further find that certain diseases prompt a different aid response and may suggest the presence of a foreign-aid reallocation due to epidemics.
However, our study does not measure the effectiveness of aid which is necessary for the design of productive policy measures that could save countless lives. Naturally, this presents new opportunities for research and raises important questions regarding the optimal allocation of aid given shocks to global health. That is, does increasing aid to all sectors serve as an effective one-size-fits-all solution? Or would a more efficient policy consist of donors reallocating aid across sectors to account for short and long-term changes in the demand for healthcare caused by an epidemic?
Editor’s note: This post is part of a series showcasing BSE master projects. The project is a required component of all Master’s programs at the Barcelona School of Economics.
Abstract
Vector autoregression (VAR) models are a popular choice for forecasting of macroeconomic time series data. Due to their simplicity and success at modelling the monetary economic indicators VARs have become a standard tool for central bankers to construct economic forecasts. Impulse response functions can be readily retrieved and are used extensively to investigate the monetary transmission mechanism. In light of the recent advancements in computational power and the development of advanced machine learning and deep learning algorithms we propose a simple way to integrate these tools into the VAR framework.
This paper aims to contribute to the time series literature by introducing a ground-breaking methodology which we refer to as DeepVector Autoregression (Deep VAR). By fitting each equation of the VAR system with a deep neural network, the Deep VAR outperforms the VAR in terms of in-sample fit, out-of-sample fit and point forecasting accuracy. In particular, we find that the Deep VAR is able to better capture the structural economic changes during periods of uncertainty and recession.
Conclusions
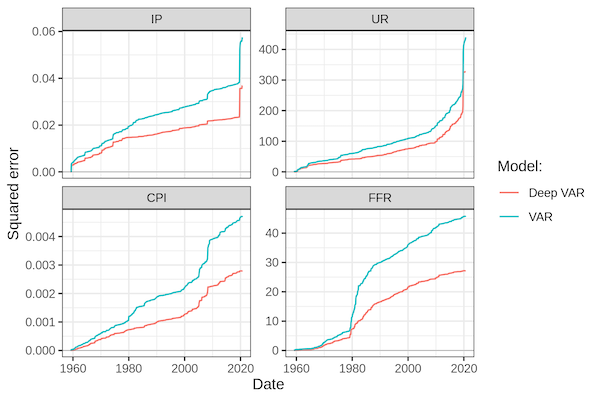
To assess the modelling performance of Deep VARs compared to linear VARs we investigate a sample of monthly US economic data in the period 1959-2021. In particular, we look at variables typically analysed in the context of the monetary transmission mechanism including output, inflation, interest rates and unemployment.
Our empirical findings show a consistent and significant improvement in modelling performance associated with Deep VARs. Specifically, our proposed Deep VAR produces much lower cumulative loss measures than the VAR over the entire period and for all of the analysed time series. The improvements in modelling performance are particularly striking during subsample periods of economic downturn and uncertainty. This appears to confirm or initial hypothesis that by modelling time series through Deep VARs it is possible to capture complex, non-linear dependencies that seem to characterize periods of structural economic change.
Credit: the authors
When it comes to the out-of-sample performance, a priori it may seem that the Deep VAR is prone to overfitting, since it is much less parsimonious that the conventional VAR. On the contrary, we find that by using default hyperparameters the Deep VAR clearly dominates the conventional VAR in terms of out-of-sample prediction and forecast errors. An exercise in hyperparameter tuning shows that its out-of-sample performance can be further improved by appropriate regularization through adequate dropout rates and appropriate choices for the width and depth of the neural. Interestingly, we also find that the Deep VAR actually benefits from very high lag order choices at which the conventional VAR is prone to overfitting.
In summary, we provide solid evidence that the introduction of deep learning into the VAR framework can be expected to lead to a significant boost in overall modelling performance. We therefore conclude that time series econometrics as an academic discipline can draw substantial benefits from further work on introducing machine learning and deep learning into its tool kit.
We also point out a number of shortcomings of our paper and proposed Deep VAR framework, which we believe can be alleviated through future research. Firstly, policy-makers are typically concerned with uncertainty quantification, inference and overall model interpretability. Future research on Deep VARs should therefore address the estimation of confidence intervals, impulse response functions as well as variance decompositions typically analysed in the context of VAR models. We point to a number of possible avenues, most notably Monte Carlo dropout and a Bayesian approach to modelling deep neural networks. Secondly, in our initial paper we benchmarked the Deep VAR only against the conventional VAR. In future work we will introduce other non-linear approaches to allow for a fairer comparison.
Code
To facilitate further research on Deep VAR, we also contribute a companion R package deepvars that can be installed from GitHub. We aim to continue working on the package as we develop our research further and want to ultimately move it onto CRAN. For any package related questions feel free to contact Patrick, who authored and maintains the package. The is also a paper specific GitHub repository that uses the deepvars package.
Editor’s note: This post is part of a series showcasing BSE master projects. The project is a required component of all Master’s programs at the Barcelona School of Economics.
Abstract
In recent years, large platforms have raised concerns that they may engage in anti-competitive practices that affect market competition. Therefore, analyzing the competition structure inside platforms is a relevant issue that has not been treated in much empirical research.
This study analyzes how a platform’s owner could affect the degree of competition among members of one group in the platform through biasing search results using rating classifications. In this paper, we perform an application to Airbnb‘s market in Barcelona given the particularity of rating is an unavailable searching filter to guests.
We found evidence that listing’s rating classification represents an important market segmentation in the Airbnb’s market in Barcelona that could imply a possible practice of biasing search results. Moreover, we found that the intensity of competition is differentiated by the rating-related segments, which means that these segments are concentrating competition.
Conclusions
We found an inelastic demand for Airbnb’s listings in Barcelona in a market that is divided by rating classification. In particular, our empirical results show the following two points:
First, the majority of hosts face an inelastic demand. These results are consistent under the two main models we used. From the nested logit model under rating segmentation, we found that when there is a 10% increase in price of available nights, there is an expected decrease in booked nights of 4.5%. These results imply that there is room to increase the price without reducing the revenues of the hosts.
Second, even though the rating is not available as a filter in the Airbnb web page, it creates an important market segmentation. This means that the competition between two listings that belong to the same segment is different from the competition faced by two listings that belong to different rating classifications. Moreover, we found differences in intensity of competition faced by listings that belong to different segments.
Finally, these results show that the existence of segmentation suggests that Airbnb is performing a rating-based market division. Yet the rating segmentation does not show a clear pattern of competition intensity in each group.
Editor’s note: This post is part of a series showcasing BSE master projects. The project is a required component of all Master’s programs at the Barcelona School of Economics.
Abstract
We construct a theoretical Overlapping Generations (OLG) model to describe how sovereign debt crises can propagate in the economy under certain financial constraints.
In the model, households work when young and deposit their savings in exchange for a dividend, banks invest deposits in assets and government bonds. Banks, subject to legal and market requirements, invest a fixed fraction of deposits and own equity in assets. When prices of bonds fall due to perceived sovereign debt risks, banks can invest less on capital goods directly affecting the business cycle. This paper simulates the deviations from steady-state produced by a shock to government securities and provides insights into macro-prudential policy implications.
We find that a sovereign debt crisis affects young and old generations differently, with the latter facing higher fluctuations in consumption. We also find that the macro-prudential policy can be effective only at very high levels on the old, but ineffective for the younger generation.
Conclusions
This paper draws three main conclusions about the impact of a sovereign debt crisis on the business cycle within the proposed OLG theoretical framework:
A decline in government bond prices leads to lower output, wages and dividend negatively affecting present and future consumption. However, this effect is different for young and old generations. In particular, the old seem to face more sudden changes and higher deviations from steady-state values when a sovereign debt crisis takes place.
The proposed macro-prudential policy does not seem to offset the impact of a fall in government bonds prices on the business cycle. In fact, almost all the macroeconomic variables of interest in our theoretical model do not change significantly, relative to their steady-state values, when the supervising authority modifies the capital requirements for banks.
A very aggressive policy on capital requirements (i.e. x=0.9 for the whole period) can compensate for the negative shock bonds prices have on dividends and, therefore, consumption for the old.
Editor’s note: This post is part of a series showcasing BSE master projects. The project is a required component of all Master’s programs at the Barcelona School of Economics.
Abstract
Mental health outcomes significantly deteriorated in the United Kingdom as a result of the Covid-19 pandemic, particularly for younger individuals. This paper uses data from the Millennium Cohort Study to investigate the heterogeneity of mental health effects of the Covid-19 pandemic on adolescents by both personality types and personality traits. Using two-step cluster analysis we find three robust personality clusters: resilient, overcontrolled, and undercontrolled.
Conclusions
We surprisingly find that resilient individuals, who generally have better mental health, reported larger decreases in mental health during the pandemic than both undercontrollers and overcontrollers
The effect seems to be driven by the neuroticism trait, such that those with higher neuroticism scores fared better than those with lower scores during the pandemic
Our findings highlight that personality traits are important factors in identifying stress-prone individuals during a pandemic.
Finance master project by Lapo Bini and Daniel Mueck ’21
Editor’s note: This post is part of a series showcasing BSE master projects. The project is a required component of all Master’s programs at the Barcelona School of Economics.
Abstract
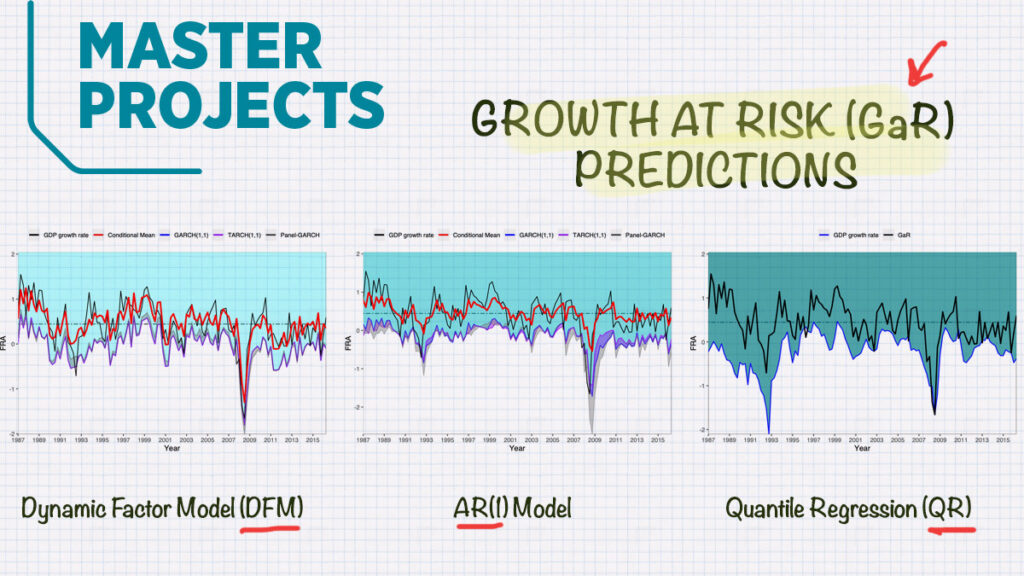
In order to analyse whether financial conditions are relevant downside risk predictors for the 5% Growth at Risk conditional quantile, we propose a Dynamic Factor- GARCH Model, comparing it to the two most relevant approaches in the literature. We conduct an out-of sample forecasting analysis on the whole sample, as well as focusing on a period of increased European integration after the 2000s. Always, including the national financial conditions index, term structure and housing prices for 17 European countries and the United States, as down side risk predictors. We find evidence of significant predicting power of financial conditions, which, if exploited correctly, becomes more relevant in times of extraordinary financial distress.
Conclusions
We propose a Dynamic Factor-GARCH model which computes the conditional distribution of the GDP growth rates non-parametrically, exploiting the dimensions of a panel of national financial conditions and compare it to the models of Adrian, Boyarchenko, and Giannone (2016 )and Brownlees and Souza (2021) out-of-sample.
Contrasting to our in-sample results, the out-of sample results exhibit a higher degree of heterogeneity across countries. While our model performs at least as good or better as the AR(1)-GARCH(1,1) specification of Brownlees and Souza (2021) in the long run, it produces unsatisfactory results for the one-step forecast horizon.
However, by focusing our out-of-sample analysis on a smaller sample around the period of the Great Recession, we not only outperform the other two models analysed, but also obtain strong indication of increased importance and predictive power of financial conditions.
We provide evidence that by correctly modelling financial conditions, they not only exhibit predictive ability for GDP downside risk, but also improve in-sample GaR predictions. Further, we show that they are relevant out-of-sample predictors in the long run. Finally, when focusing on periods of extraordinary financial distress, like the Great Recession, financial conditions become even more relevant. However, the right model needs to be applied in order to exploit that predictive power.
Editor’s note: This post is part of a series showcasing BSE master projects. The project is a required component of all Master’s programs at the Barcelona School of Economics.
Abstract
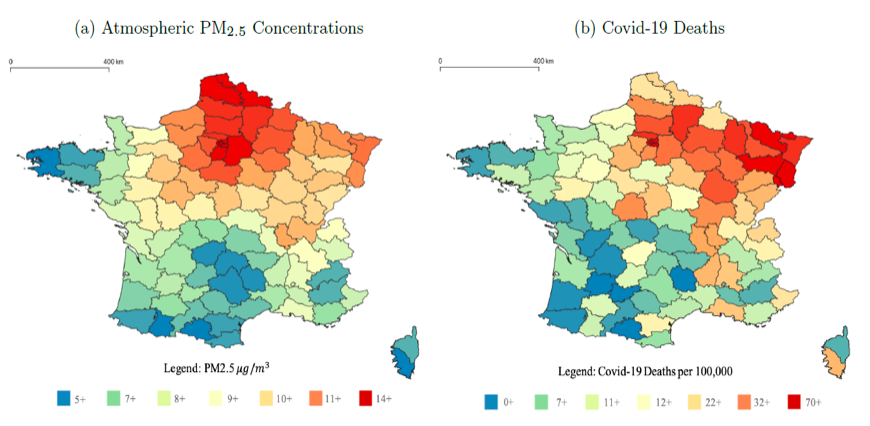
For patients infected by Covid-19, underlying health conditions are often cited as a source of increased vulnerability, of which exposure to high levels of air pollution has proven to be an exacerbating cause. We investigate the effect of long-term pollution exposure on Covid-19 mortality, admissions to hospitals and admissions to intensive care units in France. Using cross-sectional count data at the local level, we fit mixed effect negative binomial models with the three Covid-19 measures as dependent variables and atmospheric PM2.5 concentration (µg/m3) as an explanatory variable, while adjusting for a large set of potential confounders. We find that a one-unit increase in PM2.5 concentration raised on average the mortality rate by 22%, the admission to ICU rate by 11% and the admission to hospital rate by 14% (rates with respect to population). These results are robust to a large set of sensitivity analyses. As a novel contribution, we estimate tangible marginal costs of pollution, and suggest that a marginal increase in pollution resulted on average in 61 deaths and created a 1 million euro surcharge in intensive care treatments over the investigated period (March 19th – May 25th).
Conclusions
The study is a strong indication that air pollution is a crucial environmental factor in mortality risks and vulnerability to Covid-19. The health risks associated with air pollution are well documented, but with Covid-19 in the spotlight we hope to increase awareness of the threat caused by pollution, not only through direct increased health risks, but also through external factors, such as pandemics.
We show the aggravating effect of long-term pollution exposure to three levels of severity of Covid-19 symptoms in France: admission to hospitals for acute Covid-19 cases, admission to intensive care units for the most severe vital organ failures, and fatalities (all expressed per 100,000 inhabitants). Using cross-sectional data at the départemental (sub-regional) level, we fit mixed effect negative binomial models with the three Covid-19 measures as dependent variables and the average level of atmospheric concentration of PM2.5 (µg/m3) as an explanatory variable. We adjust for a set of 18 potential confounders to isolate the role of pollution in the spread of the Covid-19 disease across départements. We find that a one-unit increase in average PM2.5 levels increases on average the mortality rate by 22%, the admission to ICU rate by 11% and the admission to hospital rate by 14%. These results are robust to a set of 24 secondary and sensitivity analyses per dependent variable, confirming the consistency of the findings across a wide range of specifications.
We further provide numerical – and hence more tangible – estimates of the marginal costs of pollution since March 19th. Adjusting for under-reporting of Covid-19 deaths, we estimate that long-term exposure to pollution marginally resulted in an average 61 deaths across French départements. Moreover, based on average daily costs of intensive care treatments, we estimate that pollution induced an average 1 million euros in costs borne by hospitals treating severe symptoms of Covid-19. These figures strongly suggest that areas with greater air pollution faced substantially higher casualties and costs in hospital services, and raise concerns about misallocation of resources to the healthcare system in more polluted areas.
Our paper provides precise estimates and a reproducible model for future work, but is limited by the novelty of the phenomenon at the centre of the study. Our empirical investigation is restricted to the scope of France alone due to cross-border inconsistencies in Covid-19 data collection and reporting. Once Covid-19 data reporting is complete and consistent, we hope future studies will examine the effects of air pollution at a greater scale, or in greater detail. On the other hand, more disaggregated data – at the individual or hospital level – would allow more precise estimates and a better understanding of key factors of Covid-19 health risks and would also allow the use of surface-measured air pollution. Measured pollution data is available for France, but is inherently biased when aggregated at the départemental level, due to lack of territorial coverage. If precise data tracking periodic Covid-19 deaths becomes available for a wider geographic region, we specifically recommend a MENB panel regression incorporating a PCFE for spatially correlated errors. This will produce the most accurate estimates.
Going forward, more accurate and granular data should motivate future research to uncover the exact financial costs attributable to air pollution during the pandemic. Precise estimation of costs of Covid-19 treatments and equipment (e.g. basic protective equipment for personnel or resuscitation equipment), should feature in a more accurate cost analysis. Hospital responses should be thoroughly analysed to understand the true cost of treatments across all units.
It is crucial that the healthcare costs of pollution are globally recognised so that future policy decisions take them into account. Ultimately, this paper stresses that failure to manage and improve ambient air quality in the long run only magnifies future burdens on healthcare resources, and cause more damage to human life. During a global pandemic, the costs of permitting further air pollution appears ever more salient.
Editor’s note: This post is part of a series showcasing BSE master projects. The project is a required component of all Master’s programs at the Barcelona School of Economics.
Abstract
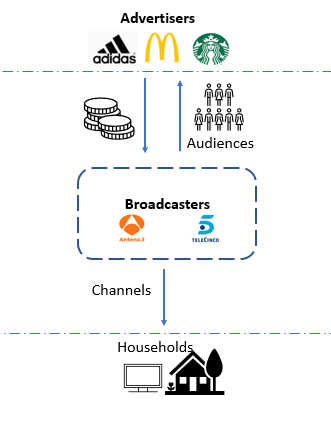
Our research arises in a context where “free” services in one market cannot be understood without taking into consideration the other side of the market. The Spanish free-to-air TV industry is a two-sided market in which viewers demand TV programs (for free) and advertisers demand advertising spots for which they pay a price that depends mainly on audience. Our main contribution to the two-sided market literature is estimating both viewers and advertisers demand to be able to understand the interactions of both sides of the free-to-air TV market.
This analysis is carried out by developing an econometric analysis of the free to air TV market in Spain that captures the reaction of viewers to a change in advertising quantity and the effect on price of ads that this would bring. We specified Viewers Demand in the Spanish free-to-air TV through a logit model to analyse the impact of advertising minutes on the audience share and, we specified Advertisers Demand by an adaptation of the model of Wilbur (2008) to understand the effect of audience share and advertising quantity on prices of ads.
Conclusions
The results of the Viewers Demand model show an elastic demand and that viewers are averse to advertising regardless of the day but during prime time they are a bit more ad tolerant, especially from 10pm to 11 pm.
On the other side of the market, the Advertising Demand model shows that advertisers are relatively inelastic to both an increase of adds and an increase in audience share. This may be due to the fact that the data available for this project is precisely coming from the most viewed channels, for which advertisers would have more inelastic demand.
As expected, the results show that advertisers are more elastic with regards to audience share than to quantity of advertising.
Data Science master project by Laura Battaglia and Maria Salunina ’20
Editor’s note: This post is part of a series showcasing BSE master projects. The project is a required component of all Master’s programs at the Barcelona School of Economics.
Abstract
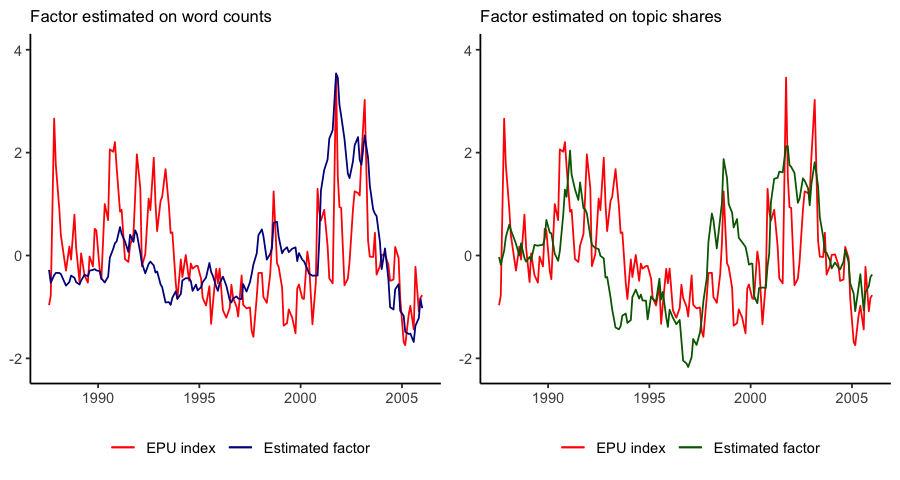
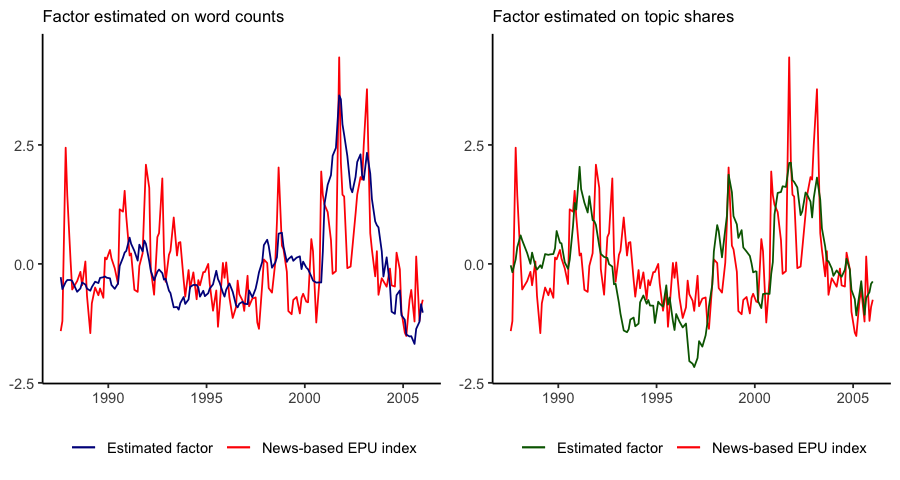
In this study, we propose an approach for the extraction of a low-dimensional signal from a collection of text documents ordered over time. The proposed framework foresees the application of Latent Dirichlet Allocation (LDA) for obtaining a meaningful representation of documents as a mixture over a set of topics. Such representations can then be modeled via a Dynamic Linear Model (DLM) as noisy realisations of a limited number of latent factors that evolve with time. We apply this approach to Federal Open Market Committee (FOMC) speech transcripts for the period of Greenspan presidency. This study serves as exploratory research for the investigation into how unstructured text data can be incorporated into economic modeling. In particular, our findings point at the fact that a meaningful state-of-the-world signal can be extracted from expert’s language, and pave the way for further exploration into the building of macroeconomic forecasting models, and in general into the usage of variation in language for learning about latent economic conditions.
Key findings
In our paper, we develop a sequential approach for the extraction of a low-dimensional signal from a collection of documents ordered over time. We apply this framework to the US Fed’s FOMC speech transcripts for the period 08-1986 to 01-2006. We retrieve estimates for a single latent factor, that seem to track fairly well a specific set of topics connected with risk, uncertainty, and expectations. Finally, we find a remarkable correspondence between this factor and the Economic Policy Uncertainty Indices for United States.
Editor’s note: This post is part of a series showcasing BSE master projects. The project is a required component of all Master’s programs at the Barcelona School of Economics.
Abstract
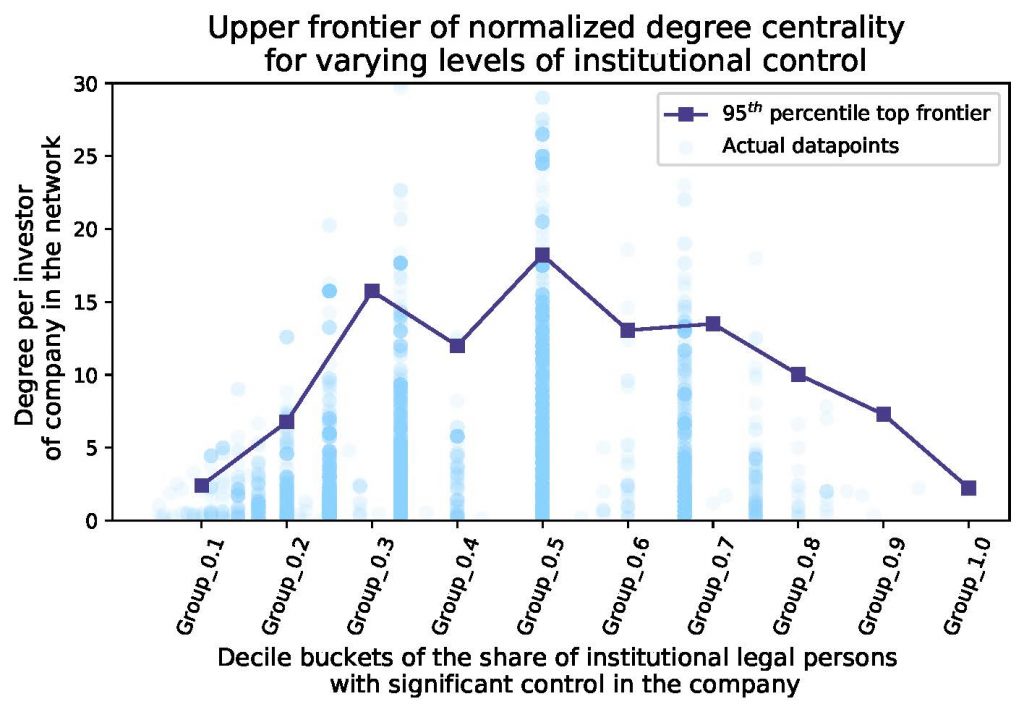
In this thesis project I analyse labour flow networks, considering both undirected and directed configurations, and company control networks in the UK. I observe that these networks exhibit characteristics that are typical of empirical networks, such as heavy-tailed degree distribution, strong, naturally emerging communities with geo-industrial clustering and high assortativity. I also document that distinguishing between the type of investors of firms can help to better understand their degree centrality in the company control network and that large institutional entities having significant and exclusive control in a firm seem to be responsible for emerging hubs in this network. I also devise a simple network formation model to study the underlying causal processes in this company control network.
Conclusion and future research
Intriguing empirical patterns and a new stylized fact are documented during the study of the company control network, since there is suggestive evidence that the types and number of investors are strongly associated with how “interconnected” a firm is in the company control network. Based on the empirical data it also seems that the largest institutional investors mainly seek opportunities where they can have significant control without sharing it with other dominant players. Thus the most “interconnected”/central firms in the company control network are the ones who can maintain this power balance in their owner structure.
The devised network formation model helps to better understand the potential underlying mechanisms for the empirically observed stylized facts about the company control network. I carry out numerical simulations, sensitivity analysis and also calibrate parameters of the model using Bayesian optimization techniques to match the empirical results. However, these results could be “fine-tuned” at different stages further, in order to have a better empirical fit. First, the network formation model could be enhanced to represent more complex agent interactions and decisions. But also, the model calibration method could be extended to include more parameters and a larger valid search space for each of those parameters.
This project could also benefit from improvements to the utilised data. For example more granular data on the geographical regions could help to understand the different parts of London more and to have a more detailed view of economic hubs in the UK. Moreover, the current data source provides a static snapshot of the ownership and control structure of firms. Panel data on this front could enhance the analysis of the company control network, numerous experiments related to temporal dynamics could be carried out, for example link prediction or testing whether investors follow some kind of “preferential attachment” rules when acquiring significant control in firms.
We use our own and third-party cookies to ensure the website works properly, measure usage, and improve our services. You can accept all cookies, reject non-essential cookies, or configure your preferences. Cookie policy
Configure cookies
Required for the website to work correctly. They cannot be disabled from this panel.
Help measure site usage and improve its content.
Allow advertising, campaign measurement, or ad personalization.
Store preferences or enable non-essential external content.